I have been thinking about agents for a while now. Not the demo kind. The ones you screenshot and share because you cannot quite believe it worked. The kind that does something useful, consistently, in production, over time. The question I keep coming back to is not how to prompt one. It is what an agent needs before prompting even matters.
Most of the conversation around agents right now is about prompting. How to write better system prompts, how to chain instructions, how to get the model to behave. That is a useful layer of the problem, but it is not the first one. Before prompting matters, there is a more foundational question: what does an agent actually need to be viable in production?
Things like agent memory, tool access, state management, identity management, observability. If you have not answered that, better prompts (and tools) will not get you to that aha moment beyond a fun demo. Everyone is optimizing layer two. I keep thinking about layer one.
This became clear to me while building Sasbot, an engineering assistant that could answer questions about our codebase, look up Jira tickets, open GitHub issues, and stay current with our docs.
Package, Topology, Deployment
The hard part was figuring out how to describe the whole thing in a way that could survive contact with reality. The instinct is to reach for a config file and start writing. But what are you actually writing down? There are three distinct things that tend to get conflated, and separating them was the insight that made everything else click.
Topology is the structure of what the agent depends on: the models it uses, the knowledge stores it reads from, the data pipelines that feed it, the tools and APIs it calls. The topology describes the shape of the agent’s world. It is relatively stable, changing when the agent’s capabilities change, not when it gets deployed to a new environment. If you add a new tool or swap in a different embedding model, that is a topology change. If you deploy to staging instead of production, it is not.
Package is the publishable artifact. It is the agent as a versioned unit, topology plus a built container image, that can be registered, discovered, and deployed. A package is what you push to a registry. It is what an operator picks up and runs. It is what you version, promote, and roll back when something goes wrong. Treating the agent as a package gives you the same operational primitives you already have for services: a clear unit of release, a clear unit of rollback, and a clear boundary between what the agent is and where it runs.
Deployment is the runtime decision layer. Which namespace. Whose credentials. How many replicas. When the ingestion cron fires. What environment variables get injected. These concerns change per environment, per operator, per cost constraint. They have no business being baked into the package, and they are not properties of the topology. They are decisions made at deploy time, by whoever is running the agent.
Conflating any two of these makes the agent hard to reproduce, hard to hand off, and impossible to reason about across environments. When topology bleeds into deployment config, you end up with agents that only work in one place. When package and deployment are not separated, you cannot promote a build without also re-specifying runtime decisions that should have been made once and left alone.
Capabilities, Not Containers
With topology separated from package and deployment, the next problem was how to express it without drowning in infrastructure details.
Most teams start by listing containers and ports. That conflates two things that should stay separate: what the agent needs and how that need gets fulfilled. If Sasbot needs a self-hosted LLM, the topology should say that. It should not have to specify the image, the port, the startup flags, and the health check path. Those are fulfillment details, and they belong to the platform.
This is the same problem Kubernetes solved for services. You declare a Deployment and a Service. You describe intent: three replicas, port 80, this container image. The control plane figures out which nodes to schedule on, how to wire up networking, when to restart a crashed container. You do not write systemd units by hand for every machine in the cluster. The spec is declarative; the platform is operational.
Agents need the same thing. When you declare that Sasbot depends on an Ollama model, you should not have to also own the ops work of running it. The declaration should be clear, as in the following example, and not a Docker Compose block with volumes, restart policies, and health checks bolted on.
models:
llm:
provider: ollama
model: llama3This led me to the idea behind provider binding. A provider declaration expresses a dependency on a capability. The platform resolves it: deploying and managing the container if it is self-hosted, injecting credentials if it is a managed API. From the agent’s perspective, both look the same, as environment variables present when the process starts. The agent does not know or care whether Ollama is running in a sidecar or whether the LLM is hitting OpenAI. That distinction lives in the deployment, not the topology.
Without this separation, every agent ends up with a bespoke configuration tightly coupled to a specific infrastructure setup. You cannot hand it to another team. You cannot deploy it to a different environment without re-wiring everything. It is not a portable artifact; it is a snowflake.
Kubernetes solved this by introducing a declarative spec as the foundation of its control plane. Operators describe intent; Kubernetes handles execution. Astro is that control plane for agents, and astropods.yml is the spec.
Here is what the Sasbot full topology looks like, declared in astropods.yml:
spec: package/v1
name: sasbot
agent:
build:
context: .
dockerfile: Dockerfile
models:
local_llm:
provider: ollama
model: llama3.2
primary:
provider: anthropic
knowledge:
docs:
provider: qdrant
persistent: true
integrations:
github:
provider: github
jira:
provider: my-jira
providers:
my-jira:
scope: [integrations]
variables:
- name: API_KEY
description: Jira API key
datatype: strin
secret: true
- name: BASE_URL
description: Jira instance base URL
datatype: string
default: https://your-org.atlassian.net
ingestion:
docs_sync:
container:
image: my-docs-sync:latest
trigger:
type: scheduleEach block declares a dependency. Here is what that means in practice.
Agent. The agent container, built from source. Nothing here says where it runs or how many replicas. Those are deployment concerns.
Models. Two dependencies, two different fulfillment strategies. The local LLM uses Ollama: the platform deploys the container and injects connection details automatically. The primary model uses Anthropic: no container, just a cloud API key injected at deploy time. The agent reads environment variables either way. The topology does not distinguish between self-hosted and managed, and it does not need to.
Knowledge. A Qdrant vector store for docs. Marking it persistent tells the platform to provision durable storage. No image, no port specified. The platform knows what Qdrant needs.
Integrations. GitHub is a built-in integration provider. The platform injects a token at deploy time, nothing to configure. Jira is not built-in, so it references a custom provider block that declares exactly what credentials are required: an API key and a base URL. The platform prompts for these during deployment, stores them securely, and injects them into the environment. This is where the extensibility of the model becomes clear. You are not limited to what the platform ships with. You define the contract; the platform handles the rest.
Ingestion. A scheduled pipeline that keeps the knowledge store current. This deserves its own section later.
A Two-Stage Pipeline
Building an agent, deploying it, and operating it in production are three different jobs, often done by three different people. An engineer or domain expert builds the agent and declares its topology. An operator takes the published package and deploys it into an environment they control. An end user interacts with what the agent exposes. Each person has a different set of concerns, and those concerns should never have to overlap.
This is what the Astro spec (astropods.yml) is designed around. It is the single source of truth the Astro AI platform uses to enforce that separation.
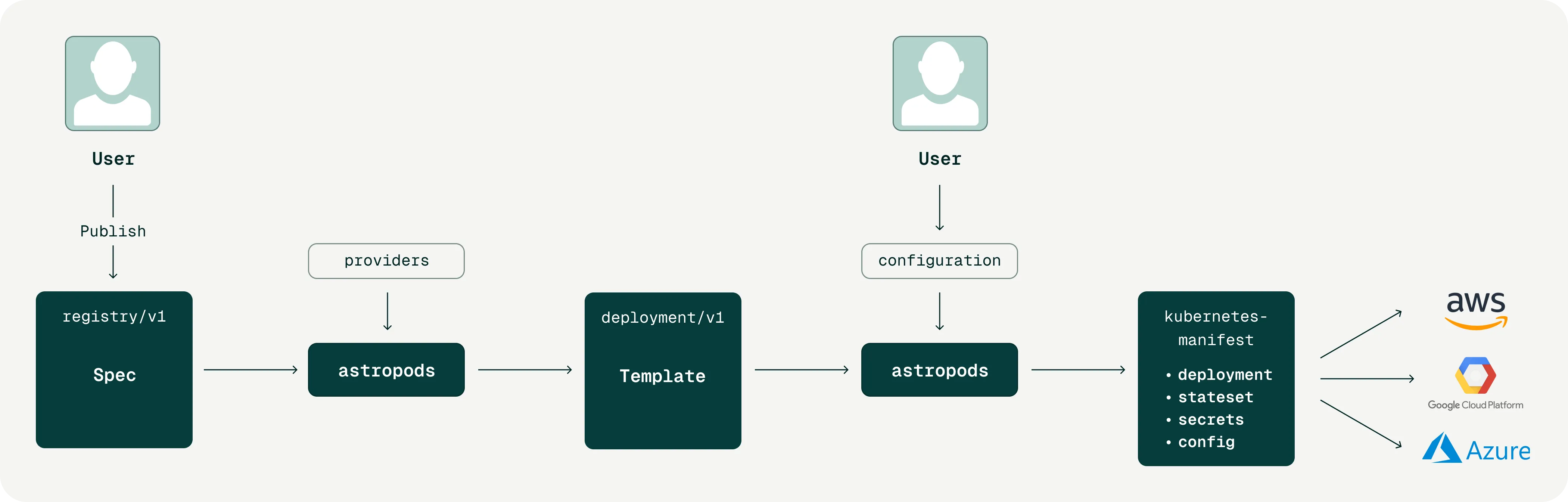
Handing the operator a raw package and asking them to fill in deployment details by hand is error-prone. It also creates implicit coupling: the operator has to understand topology decisions that are not their concern in order to deploy correctly. Instead, the Astro platform generates a deployment template from the package. It resolves everything it can decide and leaves blank only what the operator must supply. Astro keeps those layers from bleeding into each other, so no one has to understand the full stack to do their job.
The fulfilled deployment spec is also deterministic. The same spec, submitted twice, produces identical infrastructure. That makes it useful as an audit artifact, a rollback target, and a diff surface between deployments.
Without this, there is no inspectable record of what was actually deployed. Configuration is consumed and discarded. Debugging a production incident means reconstructing what was running from scattered logs and memory.
A reasonable question at this point is: why not just use Kubernetes, Helm charts, or Terraform? These are mature, widely understood, and already solve the declarative infrastructure problem. The answer is that they are general-purpose tools. They know about pods, services, and deployments. They do not know what an agent is. They have no concept of a model provider, a knowledge store, an ingestion pipeline, or the difference between a self-hosted LLM and a managed API. You can build all of that on top of Helm, but then you are writing bespoke charts that encode agent-specific domain knowledge, and every team ends up writing their own version. That is the snowflake problem again, one level up. Agents also require specific optimizations and first-class primitives that general-purpose tools cannot reason about. A read-only model can be shared across inference pods rather than duplicated. A data ingestion pipeline is a single writer; the inference agents reading from it are consumers. These are not generic infrastructure concerns. They are agent-specific scheduling and resource decisions that belong in a domain-aware control plane. That is what Astro is. It speaks the language of agents natively, so you do not have to.
Ingestion Is Not the Agent
The relationship between Sasbot and its docs ingestion pipeline feels obvious: the pipeline feeds the knowledge store the agent reads from, so they belong together. That intuition leads to the wrong abstraction.
The agent and the pipeline are related, but they are not the same thing.
Sasbot responds to requests. It runs when someone asks it a question. The ingestion pipeline keeps the knowledge store current. It runs on a schedule, independent of any user interaction. One is demand-driven. The other is time-driven. One is stateless. The other accumulates state across runs and is sensitive to ordering.
When you bundle them together, you end up managing a single workload with two completely different operational profiles. Redeploying the agent to pick up a code change restarts the pipeline. Scaling the agent up adds unnecessary ingestion workers. Triggering a manual re-sync requires touching the agent’s lifecycle.
The cleaner framing: Sasbot and the pipeline are distinct workloads that share a dependency, which is the docs knowledge store. The knowledge store is part of the topology. The pipeline is a first-class entry in the package, alongside the agent, with its own container and its own trigger semantics. They are peers, not parent and child.
This is what makes the ingestion trigger field in astropods.yml meaningful. A pipeline can be schedule-driven, startup-driven, triggered manually via API, or deployed as a long-running webhook service. These are fundamentally different operational modes. They only make sense when ingestion is treated as its own concern, declared separately, and managed independently. The spec makes that possible without splitting the agent definition across multiple files or repositories.
What Layer One Actually Looks Like
The question at the start of this post was: what does an agent actually need to function?
Not the model. Not the prompts. The infrastructure beneath them.
Building Sasbot made the answer concrete. An agent needs its dependencies declared separately from where it runs. It needs to be packaged as a versioned artifact that can be promoted and rolled back. It needs its deployment to be owned by whoever is operating it, not baked into the thing being deployed. It needs ingestion treated as a peer workload, not bolted onto the agent’s lifecycle. And it needs a platform that understands all of this natively, without asking you to encode it by hand in general-purpose tooling.
That is what the Astro spec is. A declarative, domain-aware foundation for agents in production. The same idea Kubernetes brought to containers, applied to the layer that most teams are still figuring out by hand.
Everyone is optimizing layer two. This is layer one.
RFC
We have published the Astro AI Spec (package/v1) as an open RFC. It defines the primitives described in this post. If you are building agents in production, we would like to hear from you. What works, what does not, what is missing from the model. The spec is early and the RFC is open precisely because these problems are not fully solved yet.
If you want to try it hands-on, you can build and run your first agent today. Download the Astro CLI (ast) from docs.astropods.ai and browse pre-built agents at github.com/astropods/agents to get started quickly.
We are committed to open source and will be making more of the Astro AI platform available on GitHub over time. We are also actively sharing more production-ready agents in our repository and would love contributions from the community, whether that is new agent implementations, improvements to existing ones, or feedback on the specification itself.
Saswat Das builds infrastructure for AI agents at Astro AI.